In a SERP-mediated world, you ranked. In an answer-engine world, you get quoted. The difference matters because the optimization surface changes — what made a page rank well doesn't necessarily make it citable by an AI engine, and the brands that adapt early to citation-based discovery are pulling out of the pack early. For Canadian content publishers, this rebalance favours specificity and disfavours generic content.
Experience: first-hand Canadian context
The "E" Google added to E-E-A-T — experience — translates almost directly to what AI engines use as a citation filter. Content backed by first-hand engagement with the topic, especially in a specific market, is more citable than content synthesizing other people's work. For Canadian publishers this is an asset: Canadian context (provincial regulation, currency, climate, demographics) is genuinely first-hand to a Canadian author and visibly secondhand to a non-Canadian one.
Expertise: visible authorship
AI engines preferentially cite content with clear authorship — a named author, a verifiable bio, credentials that map to the topic. Generic "Editorial Team" bylines work less well now than they did three years ago. For agencies and publishers, this means putting real names and credentials on substantive content, even when the operational reality is that content is collaborative.
Authoritativeness: who cites you
The classic SEO authority signal — backlinks from credible sources — still matters, but its expression is shifting. AI engines weight citations from sources they themselves consider authoritative, which creates a kind of reputation cascade. Canadian publishers cited by Canadian institutions (universities, government agencies, recognized industry bodies) accumulate citation-worthiness faster than ones cited by anonymous link networks. This is why content placed in real Canadian publications outperforms equivalent content placed in international content farms.

Trustworthiness: transparent and dated
Content that AI engines can verify — accurate dates, real contact information, traceable citations, transparent updates — earns trust that translates into citation frequency. Content that obscures provenance (no author, no date, no source links) is increasingly filtered out at the engine level. The good news for serious publishers: this systematically advantages careful work over volume work.
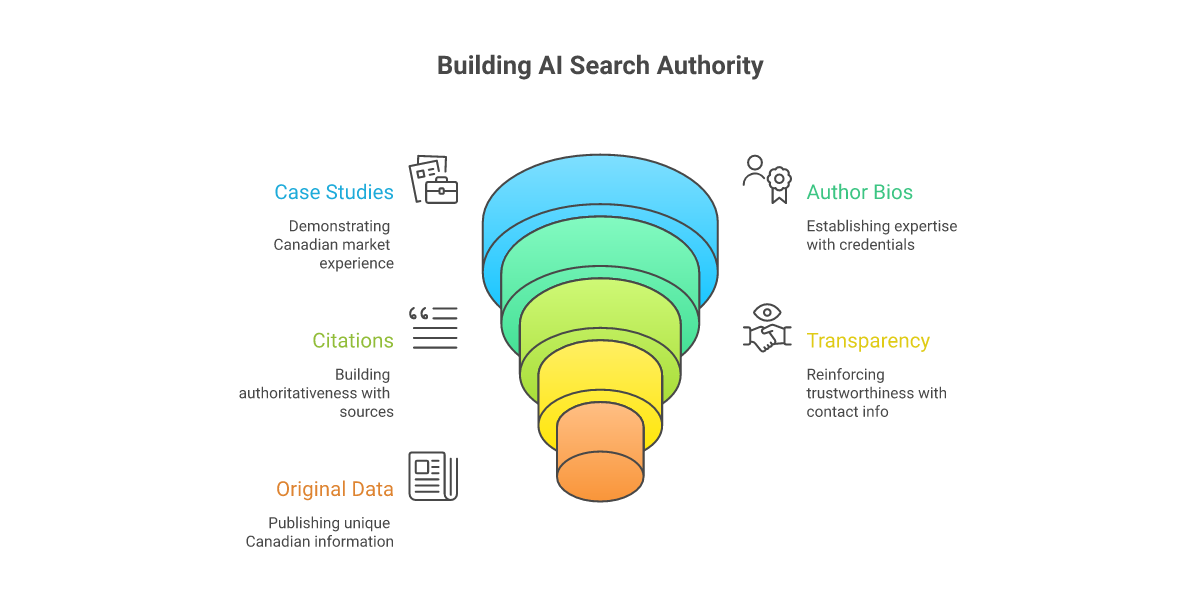
Original Canadian data is the highest-value asset
Original survey data, primary research, case studies with real numbers, internal benchmarks shared publicly — these are the assets AI engines cite hardest because they can't be synthesized from training data. CIMA encourages members to publish original Canadian data they're comfortable sharing; it's the most leveraged content investment in 2026, and it builds the kind of authority our Standards describe as professional honesty.
Keep reading
Browse the full blog index, jump to our resources, or look up terms in the glossary.